Note: This document was published in 2019, and does not necessarily reflect Chorus One’s infrastructure setup today. For the most up to date information about our security practices, please see https://security.chorus.one/.
The 2019 Chorus Validator Architecture
Joe Bowman and Meher Roy
July 2, 2019
1: Introduction
This document presents the inner workings of Chorus validators currently operational on the Cosmos Hub, Loom’s PlasmaChain and the Terra network. Our team has spent >18 months thinking about, designing, deploying, maintaining and improving on our technical architecture.
Section 3 describes the high-level objectives we chose to design our validator(s). This is followed by a description of the main components and their role in the infrastructure. Focus then shifts to architecture diagrams and detailed descriptions of the components. Finally, we will cover the security features of our IT estate. The penultimate section will concern itself with future improvements followed by a conclusion of the key ideas.
This document is a description of the current state. The design will keep improving, which will necessitate updates to this document.
2: Table of Contents
The 2019 Chorus Validator Architecture
3: Guiding Principles and Objectives
5: Architecture Diagrams and Detailed Component Descriptions
6: Security Layers of Chorus Validator(s)
6.3: No Public-facing SSH Ports
6.8: Host-based Intrusion Detection Systems (HIDS)
6.9: Least-privilege security model
6.10: Limited-lifetime Lease-based Credentials
6.12: Hardware Security Modules (HSMs)
7: Gaps and Future Improvements
7.1: Leveraging Trusted Execution Environments as an Additional Line of Defense
3: Guiding Principles and Objectives
At the inception of Chorus in early 2018, we chose a set of guiding principles that determined the points on which our technical energy would be focused. In the following, we cover all of the key principles with an explanation of why they were chosen:
- Security: A validator is subject to severe financial penalties in case of key compromise and duplicate signing of blocks. Ergo, the operational procedures of a validator must guard against these catastrophic events. Ultimately, a validator is like a castle with precious crown jewels to be defended. Our architecture must erect several barriers that prevent external attackers from getting any level of access over the key or signing logic. Section 6 covers these barriers.
- High Availability: Many networks impose financial penalties for extended downtime. It is generally advisable for validators to have greater than 99% uptime. We’ve gone the extra mile and are regularly delivering >99.9% uptime in anticipation of future networks that penalize availability to a higher degree.
- No privileged datacenter: This is a key differentiating principle between Chorus and other validators. Chorus is a distributed company, with personnel spread across Asia, North America and Europe. Many validators, such as Iqlusion and Figment, have a single data center at the center of their operations. This data center is accessible by a select group of company personnel for maintenance activities. This works since these validator firms are physically centered in one location. As a distributed firm, we do not have the luxury of quick geographical access to one particular location, nor the luxury of maintaining personnel redundancy at a particular location. For instance, if the privileged data center were to be near Meher's home in the US, non-US engineers couldn’t access it swiftly and company operations would be jeopardized should his immigration status in the US be revoked. This constraint has led us to an architecture independent of any particular geography - our security-critical validation servers are spread across Europe and North America.
- Minimize maintenance operations conducted under duress: Teams maintaining validators are all too familiar with incidents requiring quick responses such as server failures, configuration issues, network attacks, etc. The hard part about validator incident response is the need to perform critical response operations while financial and reputational damage occurs due to downtime. Imagine yourself as a validator operations personnel conducting security-critical operations, while the validator is losing $10k an hour for its delegators. This is a stressful situation, as you can imagine.
We believe there is an enormous risk when critical operations are combined with financial pressure. At Chorus, we’ve instituted a design that minimizes our team members’ need to conduct critical troubleshooting operations under financial duress. Our troubleshooting operations are usually done without any financial value on the line.
- Make security critical infrastructure broadly maintainable: Parts of the architecture will be security critical, and validator teams restrict access to these parts to a select number of trusted personnel. This creates risk and dependency on a small number of personnel to maintain validator operations. We are taking steps that will allow an extended circle of team members to maintain our validators without having sensitive access. These steps will be detailed in Section 7.
Later in the article, we shall demonstrate how these principles have shaped and strengthened our infrastructure. The key takeaway is that Chorus had a unique problem statement to build high reliability geographically dispersed infrastructure for a distributed team.
4: Overview of Key Components
There are seven major components to our validation architecture. These components are: validation servers, key infrastructure, signing coordinator, sentry layer, central services, logging & monitoring and analytics. Figure 1 shows the 7 components diagrammatically, and in numerical order by which they will be described. We give an overview of each component, the infrastructure & tools used to deploy that component and major design decisions taken pertaining to that component. Section 5 will detail how the components and their subcomponents connected with each other. Access control mechanisms placed at the various connections are detailed in Section 6.
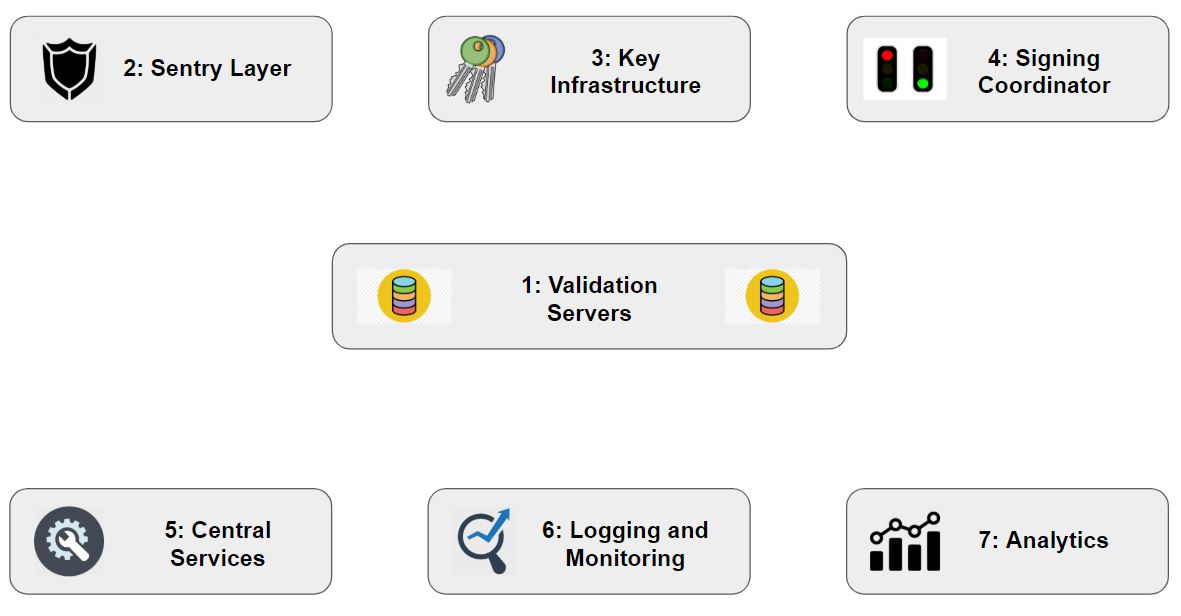
Figure 1. The main components and the order in which they will be covered
4.1: Validation Servers
Validation servers are the machines which decide which block gets signed, and broadcast to the network. These machines run the core clients of all the networks we validate on, the Tendermint KMS, maintain memory pools of transactions for these networks, propose blocks and verify the veracity of accounting transactions. Security and high uptime of these machines is critical to the validator operation.
It is recommended for validation servers to not hold the validation keys of the validator, as compromise of the servers could lead to theft of key material. We use Hardware Security Modules (HSMs), specialised devices that prevent key theft, to store key material.
Major decisions we faced regarding validation servers were: How many validation servers to use, where to host them and what software to run on them. Security policies pertaining to these servers will be covered in Section 6.
First of all, let's visit the question of where to host these machines. There are 2 main options: Rely on a cloud provider such as AWS to provision these machines for Chorus. Or purchase servers, and purpose them as validation servers, in Tier IV data centers with 100% network uptime guarantee.
The main argument for validation servers on the cloud is the scalability and elasticity of capacity & the business operating freedom gained from a leasing model. This is counterbalanced by some significant short-term downsides. The first is that a majority of cloud machine offerings are at risk from, as of yet undiscovered and some previously discovered, speculative execution attacks. These attacks could potentially allow attackers to access sensitive infrastructure secrets if the server deployments are not setup correctly. Second, cloud machine offerings generally do not provide the ability to insert custom Hardware Security Modules in the machines. This would mean that validation keys would need to be stored and accessed on a Cloud HSM service like Amazon CloudHSM. To this date, neither Amazon nor Google CloudHSM offerings allow us to leverage Ed25519 keys required for the Cosmos Hub. They are also 12X more expensive per year compared to YubiHSM2, and would have required us to develop custom integrations with network clients. Third, many cloud offerings that are/can be made resistant against speculative execution attacks still don't allow companies such as ours to have full control over the software stack running on the machine. Therefore, we decided against putting our validation servers on clouds such as AWS and Google Cloud.
The above is no permanent indictment against validation servers running in the cloud. We believe that secure setups can be built with validation servers running in the cloud. Chorus will upgrade to such an approach in the future to make better use of both cloud key management and cloud machines. A later section outlines this possibility.
Once the cloud was eliminated for validation servers, we were left with executing the purchase of servers, and the selection of Tier IV data centers to host the servers. We onboarded two validation servers, one in North America and the other in Europe; managed in data centers operated by two different service providers. As explained in a later section, an active/active architecture has both of these validation servers work concurrently on blocks received from the networks.
Server placement across both sides of the Atlantic has the advantage of complete power and network connectivity isolation for the two servers. Even if the entire electrical grid of North America would go down, Chorus validator would keep signing blocks from Europe. This architecture also has us less dependent on any individual data center vendor (and national regulatory framework) and changes in their policies. On the other hand, the downside introduced by this choice is that the Chorus validator suffers internal signing latency (~10-80 ms) due to communication overhead required to coordinate these two servers across the Atlantic. This downside became apparent in Game of Stakes, an adversarial test network. Because of its adversarial nature, network message broadcast was not very consistent, and Chorus had a higher rate of missed blocks in normal operation compared to other validators centered in just one geographical location. This downside is immaterial in the main networks, and has been mitigated by upgrades in our signing/coordination infrastructure. If it were to assume significance, we can always change the locations of servers to address the issue completely.
Both data centers operate monitored closed circuit television, and are manned by both security and technical personnel 24/7/365. Access to racks is limited to the providers’ personnel via biometrics and access card controlled man-traps. The data centers are carrier neutral and connected via diverse routes to multiple tier 1 connectivity providers, and are monitored 24/7/365 by either a remote or on-site Network Operations Center (NOC). Similarly, both are connected to multiple power substations, and are backed by at least N+1 generators. As a result, both vendors offer 100% network connectivity and power SLAs. In addition, in the event of hardware failure, vendors are subject to a one hour hardware replacement SLA.
4.2: Sentry Layer
Sentries are full nodes (for a specific network) placed between the public Internet and the validation servers. Sentry nodes ensure that validation servers are not directly exposed to the public Internet, connect to other full nodes on the network, gossip transactions plus blocks, keep validation servers up in sync with the network, and act as the first line of defense against DDoS attacks. They can also be repurposed for the role of transaction filtering to guard against transaction spam attacks. We've deployed sentry nodes on AWS, as they are less security critical than the validation servers. For the Cosmos Hub, six Chorus sentries are placed in the United States, the European Union and Korea. Geographical redundancy helps the network gossip protocol, and keeps our validators better in sync with the network as we are able to leverage the cloud provider’s backbone network to gossip messages between continents offering us lower latency than if we were peer the same servers over the public Internet.
A subset of Chorus sentries are private sentries. Private sentries do not actively accept inbound network connections and make outbound connections via a NAT gateway. They are connected to private sentries of other validators to create an inter-validator gossip network. Chorus has partnered with several validation firms to build a private sentry network. Private sentries act as a second line of defense against DDoS attacks. Even if all Chorus public facing sentries were successfully taken down, our validators would stay in sync with the Cosmos network via the private sentry layer.
In addition to sentries, Chorus runs load balanced seed nodes on AWS. The primary purpose of these nodes are to crawl the Tendermint p2p network and keep an updated address book of all other full nodes. Newly joined, or badly connected, full nodes are able to connect to the Chorus seed nodes, and update their address books. A secondary purpose is to allow developers to make blockchain data queries during their application development lifecycle. Chorus seed nodes are a public utility run to ensure the health of various networks onboarded by the firm. For Cosmos, they are available at: https://cosmos.chorus.one:26657 and for Terra, at https://terra.chorus.one:26657. The seed nodes also run copies of the light client daemon (LCD) for both Cosmos and Terra, available to the public on https://cosmos-lcd.chorus.one:1317 and https://terra-lcd.chorus.one:1317 respectively.
4.3: Key Infrastructure
Validation keys that sign all blocks on Tendermint networks, are critical security parameters of our validation infrastructure. These keys are provisioned in YubiHSM2 Hardware Security Modules, and physically inserted into the validation servers. The generation of keys, configuration of key material into hardware security modules, backup of keys and restoration of keys are important processes for a validation company since any compromise in the supply chain will compromise the validator. Chorus has invested significant resources in its key infrastructure in order to build it compliant with the standards promulgated by NIST.
The central feature of the Chorus Key Infrastructure is the division of roles pertaining to the key lifecycle between different team members. We've created four internal roles for the various stages of the key infrastructure lifecycle and allocated them to different team members:
- Cryptographic officer(s): Cryptographic officer(s) are the root of trust in the Chorus Key Infrastructure. Cryptography officers are tasked with the generation of keys via properly planned and documented ceremonies, the input and backup of key material in the Hardware Security Modules, and the execution of all cryptographic ceremonies. Cryptographic officers are the only team members with access to the raw key material in some short timeframe. The timeframe of direct exposure to sensitive key material is minimised via sound ceremony design. Key generation takes places on hardened air-gapped laptops with wireless connectivity and persistent storage disabled.
- Key share custodians: Chorus keys are provisioned into HSMs and backed up. For backup, validation key material is split into multiple shares using Shamir’s Secret Sharing. Shares are allocated to different key share custodians. Key share custodians are tasked with the safekeeping of key shares using geographically distributed safe deposit services. If any key needs to be re-created in the future, m of n schemes between key share custodians are required for the recreation of keys.
- Cryptographic Administrator(s): Cryptographic administrators are tasked with the preparation of equipment and documentation pertaining to cryptographic ceremonies. Equipment includes factory reset Hardware Security Modules, air-gapped laptops, bootable USB drives etc. Cryptographic administrators also have access to limited administrative functionality on the HSMs. HSM systems and ceremonies are designed to not expose any sensitive key material to the administrators.
- Cryptographic Auditor(s): Cryptographic auditors are responsible for the audit of logs/records from hardware security modules and ceremonies. Audits of signature logs from Chorus Infrastructure are also in their purview. They are critical to keeping the Chorus Key Infrastructure follow the correct standards, and institute corrective action when needed.
Software deployments in the Chorus Infrastructure ensure that team members occupying certain roles have the correct permissions and the least privileges required for their role. Let's take an example:
Assume the scenario is the configuration of 2 HSMs with the validation key of a newly onboarded network. Post configuration, the HSMs will be plugged into servers to sign blocks. Logs from the HSM will be studied by the Cryptographic Auditors. One day, the HSMs wiill be retired and sensitive key material must be deleted from them. In this particular HSM, permissions must be set up such that:
- Cryptographic officers, and only cryptographic officers, are able to generate, import or export any (encrypted) sensitive key material, and this key material must be exported in a cryptographically wrapped form.
- Cryptographic Auditors, are just able to extract logs from the HSM, and study them without having access to key material.
- Cryptographic Administrators are able to reset HSMs and establish connections between software processes running on servers and HSMs without having any access to key material.
In order to perform fine-grained provisioning over Chorus keys, we’ve developed HSMman, an in-house key management tool. This tool automates the provisioning and configuration management of all of our HSMs. We have the capability to quickly provision new HSMs with key material as needed. Chorus also has built its key architecture to have lots of spare capacity and is able to onboard new networks while running sensitive cryptographic ceremonies sparingly. Another critical feature of HSMman is its ability for encrypted key shares to be distributed between ceremony personnel over the internet. It enables key shares to be communicated securely out-of-band between two air-gapped computers, such that we are able to conduct the sharing of cryptographic material remotely whilst maintaining its absolute secrecy. One-time encryption keys are used for the encryption and distribution of key shares.
4.4: Signing Coordinator
Chorus runs an active/active validation architecture. This means that there are two servers, one in Europe and one in North America, attempting to sign blocks on the PoS networks concurrently. Whenever a new (valid) block is proposed by a different validator, both these servers compete to get "signing rights" for that particular block. One of the servers ends up winning the race, and it's that server that signs the block. The other server is prohibited from signing any block on the same HRS (height,round,step) combination.
We've invested in this particular architecture for the following reasons:
- Datacenter agnosticity: We can add or remove new servers in other data centers, and have them join the system with low effort.
- High Availability leading to lower error rate: If either of these servers fails (hardware, networking or configuration issue), the other server can keep on signing on behalf of Chorus. There is no manual effort at the time of server failure - the system automatically handles the scenario. The server that failed can be troubleshot over an extended period of time. Essentially, this means that all repair efforts are done in a calm environment. Had we had only a single server, or the need for manual recovery from failure of a server, all of those operations would need to be done in a state of duress.
This active/active architecture required us to design a signing coordinator - a set of components that allocate "signing rights" to servers; and ensure that only a single server can have a signing right at a particular HRS (height, round, step).
The major piece of the signing coordinator is a strongly consistent, multi-region, multimaster database operated by AWS. We've used their DynamoDB product to instantiate this database. A server's signing right is represented as the entry of a database row with the primary key corresponding to the HRS of the particular signing step. Both servers attempt to insert entries into the database for a particular HRS. Once the first server inserts the entry, the second server will be forbidden from entering a different entry with the same HRS in the database. In effect, the database acts as a pigeonhole for every signing step. Two competing pigeons try to enter the hole, but the pigeonhole is configured to accept only one of the pigeons.
On the signing server-side, prior to signing any block, the servers must first complete the corresponding entry in the DynamoDB database. Only when they are successful in inserting the entry, will they be able to sign and move forward. This logic, on the signing server-side, was implemented on top of the Tendermint KMS in Rust. Chorus plans to open source the components of its active/active setup sometime in the Summer of 2019.
4.5: Central Services
Central Services is a catchall component that comprises some of the important core utilities required by the validation infrastructure. If the entire validator estate is like a city, central services is the raw infrastructure - water, power, waste management - required by most of the other components.
In the Chorus validation architecture, Central Services contains the following services:
- DNS: In totality, the Chorus validation estate has >50 machines working for the different networks. These include Sentry nodes, validation servers, configuration management servers etc. it quickly becomes prohibitive to refer to all of these machines by their IP addresses. Therefore, an internal DNS system is required to assign human memorable names to the machines, and be able to resolve these names to the machines. For example, the Chorus DNS might assign a name like sentry01.loom.production.chorus.internal to a sentry node of the Loom network production environment. Such estate-wide DNS records are maintained centrally but deployed to each VPC for redundancy.
- NTP: NTP machine in central services is used for clock synchronisation of all other machines running on the Chorus validation estate. Synchronised clocks are important when verifying TOTP (Time-based One Time Passphrases) for two-factor authentication, reviewing log files (we can accurately assert that an event on server A did or did not happen before an event on server B, because the clocks are synchronised), and authentication leases.
- VPN: Virtual private networks (VPNs) are used for any access into the Chorus infrastructure. VPNs ensure that all communication is encrypted and also ensure secure remote access for all Chorus team members logging into the production systems. This means we are able to completely avoid the exposure of port 22 (SSH) to the outside world, while maintaining full connectivity when travelling that whitelisting of IP addresses doesn’t allow.
- Vault: For any infrastructure, secrets management is an important concern. Infrastructure and application secrets are those secrets that one component of the infrastructure uses to authenticate itself, fully automated, with another component of the infrastructure. As an example, the validation server must authenticate itself with the Hardware Security Module. The validation server must have access to some access token that allows it to authenticate with the HSM. Infrastructure secrets must not be stored in repositories or in plaintext on disks, since compromise of repositories or disks can lead to compromise of the secret. Storage of secrets centrally also allows for easier rotation of secrets - an important functionality to ensure the ongoing security of the infrastructure.
At Chorus, we use Vault, a HashiCorp product, for all infrastructure secrets management. Tokens, passwords and certificates are stored, rotated and distributed from Vault. Vault is considered to be of a lower level of security than secrets stored directly in HSMs. Therefore cryptographic key material is not stored within Vault. Section 6 covers the security features we’ve implemented using Vault.
We also use Vault to generate short-term role-based credentials for cloud providers and databases, such that persistent user accounts or roles are not required for the majority of use cases. Low TTLs means that any inadvertent exposure of any credentials has a far more limited impact.
Finally, the tokens generated for the above short-term credential sets are single use. If a user were to compromise a validation server, and query vault for the authentication password for a key stored on a HSM using the most recently used token, their request would be rejected.
- Intrusion Detection: Host-based Intrusion Detection System (HIDS) comprises an application installed on every machine in our estate to provide constant information on state of files, users and permissions. In the event that some file or parameter changes unexpectedly, as a result of an intrusion, or remote code execution, we are able to react quickly to nullify the attack.
- Vulnerability scanning: Vulnerability Scanning is conducted against our estate such that when a new CVE or security vulnerability is announced, we will be automatically alerted to the presence of any affected packages installed on our servers, and can act swiftly to remedy.
4.6: Logging & Monitoring
Observability of an Infrastructure estate is one of the most basic, but most powerful tools at the disposal of an engineer. It allows one to view, understand, proactively respond, and be automatically alerted to changes in the behaviour or performance of servers.
It can be broken down into three main streams:
- Server Metrics: Information about CPU usage, memory usage, disk utilisation, network performance and IO performance allows better predictions of resource usage. These metrics can be used to diagnose when application upgrades begin leaking memory, and can prevent outages from arising when disk utilisation nears 100% or when components begin to fail.
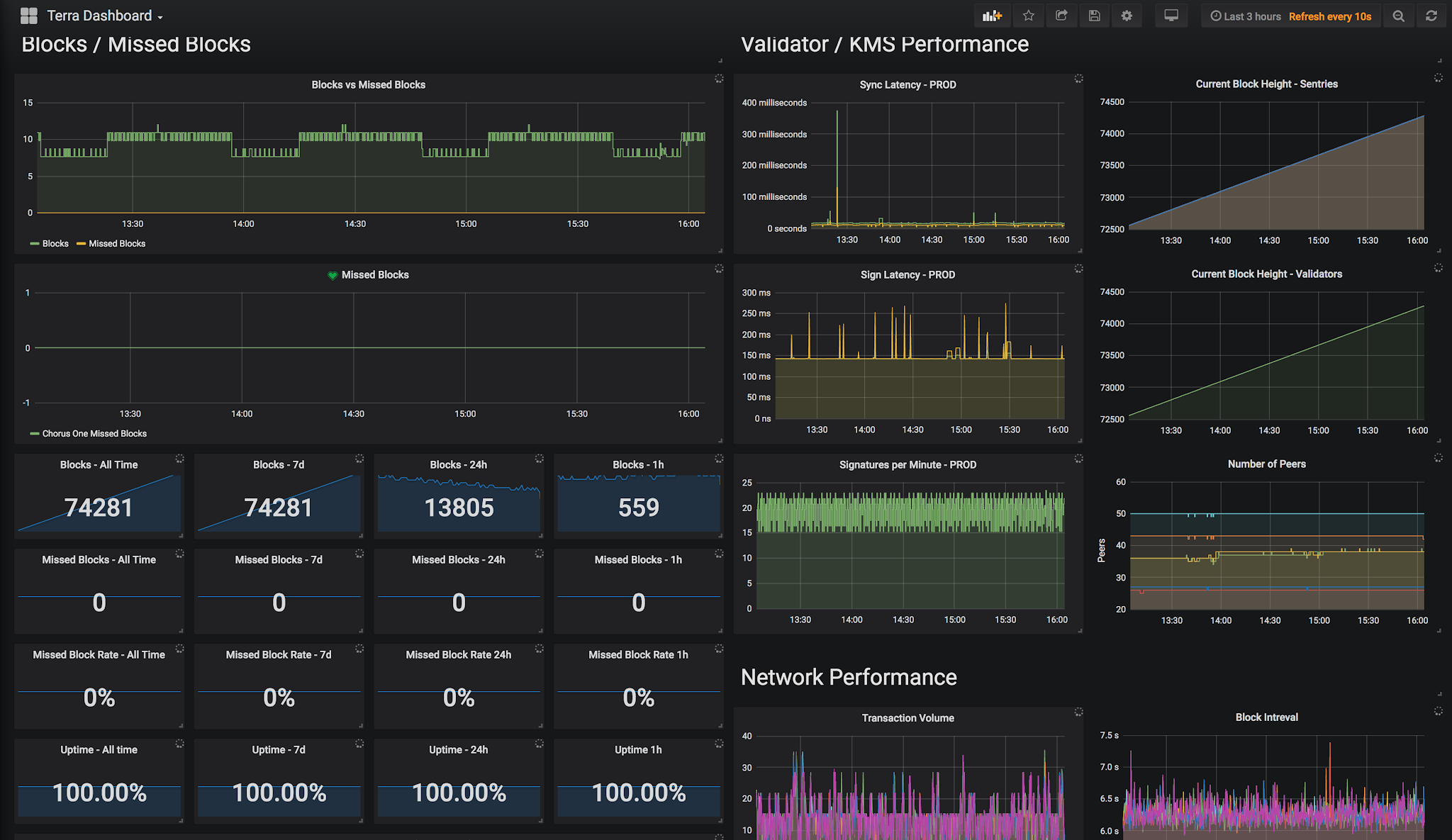
Figure 2. A screenshot of one of our monitoring dashboards
- Application Metrics: Metrics produced by applications are collected, aggregated and used for alerting us to potential issues with running applications. In addition to existing metrics endpoints exposed by cosmos-sdk and loom, we also monitor RPC and LCD endpoints to provide supplemental data regarding the networks on which we validate.
- Logging: All application logs, system logs and authentication logs are streamed encrypted to a centralised logging facility (utilising Fluentd and Logstash, via a high-availability queue so logs are not lost if the log processor fails), where they are parsed, tokenized, indexed and stored in Elasticsearch. These logs can then be used to automatically trigger alerts (on known strings, such as ‘CONSENSUS FAILURE’ or ‘Disk Full’), and can be shared with developers without having to give SSH access to the server. Having all the logs in a single place also aids debugging issues and determining causes of failure, as you are able to visualise in a single pane the order in which events occurred.
We use a combination of Prometheus, Menoetius, Grafana and Influxdb in a high-availability layout for our internal monitoring, coupled with an external alerting service, which manages 24/7 our on-call rotation, and alert escalation processes. Our internal monitoring services is in turn monitored by an external monitoring service, so failure of the internal service will itself raise an alert, such that we do not blindly miss outage events due to monitoring service downtime. Also monitored are our external endpoints - from website and blog through to seed nodes and sentries. If any of these items experience over one minute of downtime we are immediately alerted.
In terms of logging, we run a setup comprising Elasticsearch, Logstash and Kibana, commonly referred to as the ELK stack. Logs are collected on each node and pushed over Fluentd over https to a high-availability queueing service, so that logs are not lost if Logstash processing nodes experience an outage.
The onboarding of any new network is not deemed complete until we have sufficient logging and monitoring in place to support the operation of that network.
4.7: Analytics
In order to better inform our business decisions, and to bootstrap future development we have invested a significant amount of effort in writing an analytics engine called Blockstream. It connects to and subscribes to events from all the blockchains on which we validate. Each event has an observer, to which one or more processing modules can be assigned. The processed data can be indexed and stored in a way that allows us to run complex queries against the data that would be computationally expensive if they were run against the chain each and every time. It has been designed to be blockchain agnostic, and easily extensible to incorporate new chains with little effort.
5: Architecture Diagrams and Detailed Component Descriptions
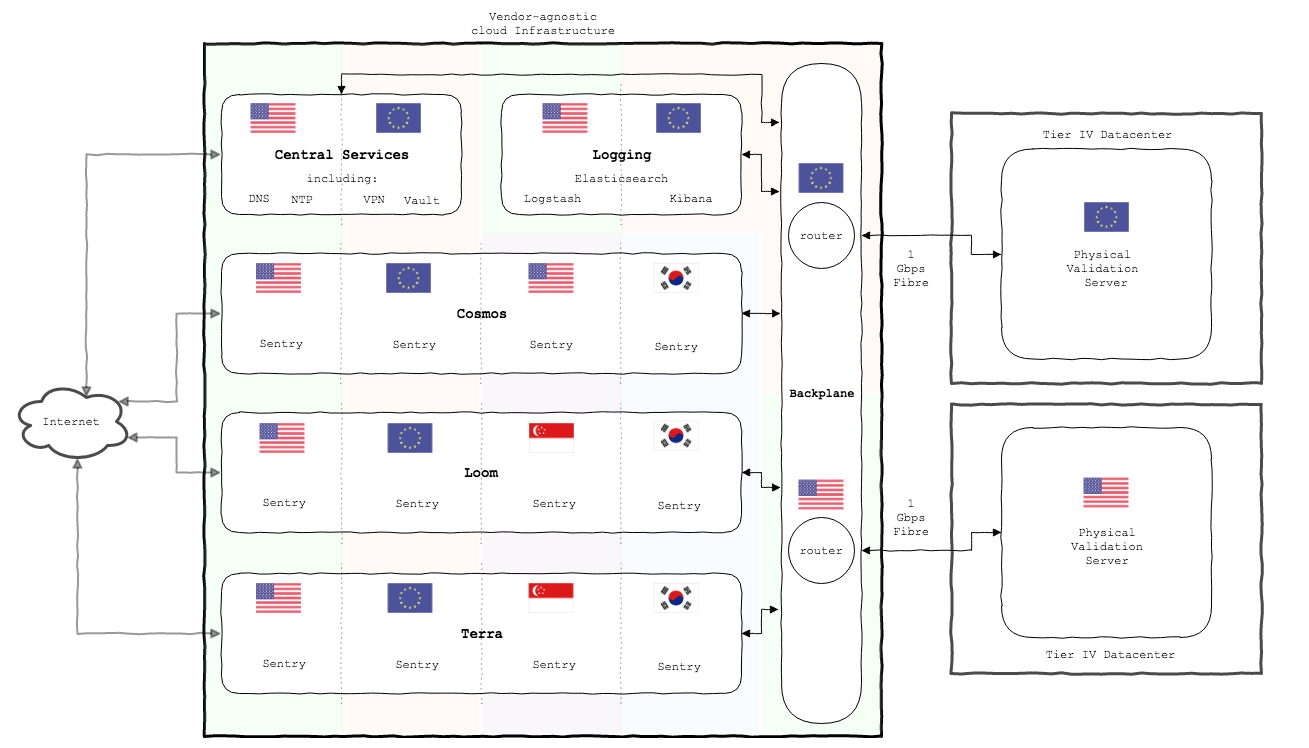
Our Infrastructure is broken down into logical units, that we refer to as ServiceInstances. Each ServiceInstance has a specific purpose (e.g. cosmos network, logging, central services, etc.) and spans multiple cloud-provider regions, in order to ensure no service can fail due to an outage of a single region or vendor.
Cloud-regions within a ServiceInstance are peered with one another ensuring we are able to leverage cloud-providers' backbone networks to leverage the lowest possible latency connections between sentries.
Access controls (discussed further in Section 6) are in place such that individuals are unable to traverse between ServiceInstances. Only traffic that is explicitly permitted can pass between nodes, so compromise of a node in the Loom ServiceInstance should not be able to impact the operation of our Cosmos validator.
Furthermore, each ServiceInstance comprises public and private subnets. Nodes that expose ports to the public Internet reside in the former, with non-public nodes sitting in the latter routing outbound connections through highly available NAT gateways.
Figure 3. High-level overview of the current Chorus sentry and validation infrastructure
6: Security Layers of Chorus Validator(s)
This section aims to cover the specific layers in our multi-layer security model, and how these steps combine to create an industry leading validation infrastructure.
Figure 4. Access control diagram of the Chorus infrastructure
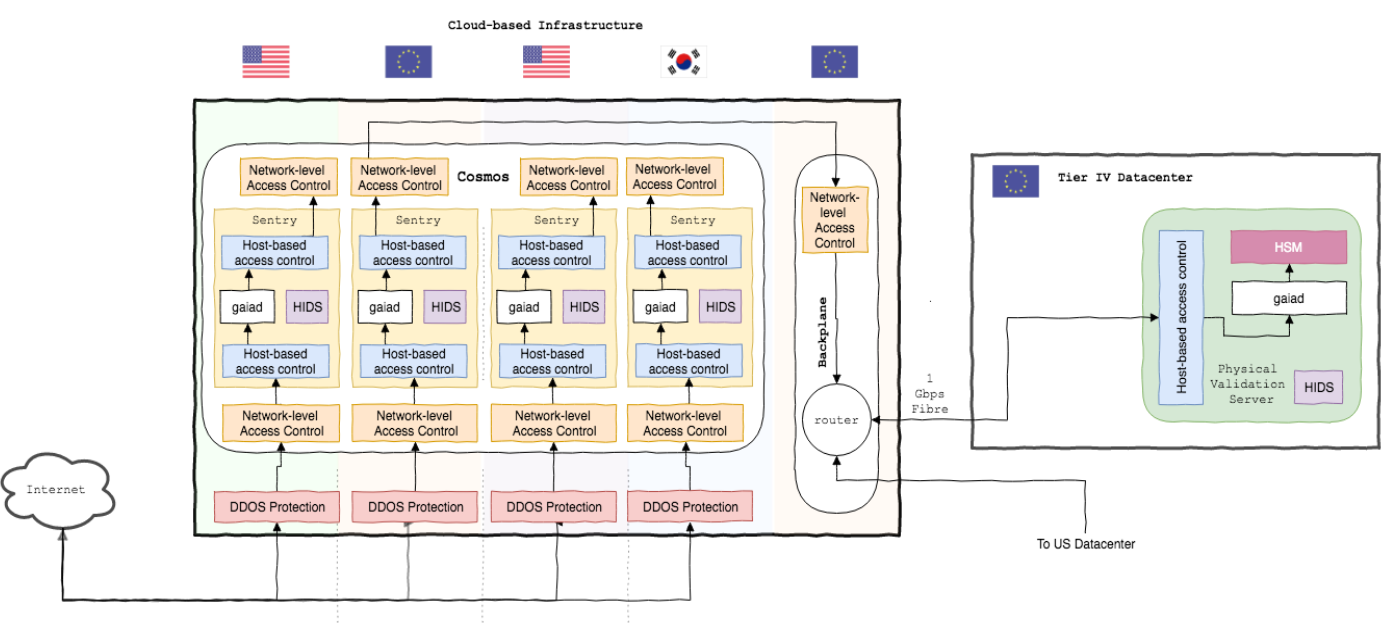
6.1: TLS Endpoint Encryption
By using TLS encryption we can protect communication between entities from Man in the Middle attacks (MitM Attacks, Wikipedia). With the exception of the P2P ports, all publicly available endpoints (and a vast majority of internal services) are secured using TLS. With the advent of free SSL certificates through LetsEncrypt, TLS secured communications are within reach of everybody.
6.2: DDoS Protection
In order to mitigate the impact on hosts of denial of service attacks (Denial of Service Attacks, Wikipedia) we route inbound packets from the public Internet via cloud-provider DDoS protection.
In addition to our public sentries, we run 'private' sentries behind NAT (Network Address Translation, Wikipedia) gateways that only permit outbound connections so that in the event of a targeted attack against our public nodes, we will be able to continue receipt and transmission of P2P packets to and from the wider network.
These private sentries are also ‘privately peered’ with carefully selected partners via cloud-provider network peering, to ensure both parties benefit from each others’ connectivity even in the harshest of adversarial climates.
6.3: No Public-facing SSH Ports
Operation of our nodes is ultimately conducted via SSH - although we minimise this as much as humanly possible through automation - but as poorly SSH protected SSH endpoints are a primary target for any intruder, we do not expose SSH on any port (exposing on a non-default port is considered security-through-obscurity, and a poor countermeasure), preferring to utilise an encrypted VPN for all control traffic in and out of our infrastructure.
6.4: VPN
As discussed above, all administrative and operations traffic in and out of the network traverses over a VPN. Each ServiceInstance has it's own VPN to allow control over access to ServiceInstances on a least-privilege basis. Users' access to a VPN requires a certificate (that can be revoked immediately in the event of loss, disclosure or termination of position), user and password combination and multi-factor One-time Passcode (One-time Passcode, Wikipedia) token.
6.5: SSH: PKI and MFA
Once connected over VPN, further SSH connectivity to any given node inside our infrastructure requires the user's public key (PKI) and MFA (Multi-factor authentication) token. User access to nodes is provided per-node on a least-privilege basis. As mentioned above, SSH traversal between nodes and/or between ServiceInstances is not permitted.
6.6: Network-level Firewalls
Access between networks (ingress from public Internet, public -> private networks, communications between internal services, egress to public Internet) is controlled by per-service firewall rules. Only packets to and from whitelisted IPs and/or ports are permitted through the firewall.
6.7: Host-based Firewalls
In addition to network-based firewalls above, ingress and egress of data to and from any given host is controlled by host-based firewall rules. Packets failing these rules are logged such that unauthorized egress of data will be alerted upon.
6.8: Host-based Intrusion Detection Systems (HIDS)
Our HIDS triggers events based upon rulesets when certain conditions are met (for example, attempted write to configuration files, prohibited system calls, etc.) and raises an alert to the team, allowing us to respond swiftly.
6.9: Least-privilege security model
All user access accounts permissions are based on a least-privilege model (Principle of Least Privilege, Wikipedia), where the access afforded to a user is based upon the minimum permissions required to fulfil their duties. This applies to every service where user accounts are created, and for all users regardless of their position in the company.
6.10: Limited-lifetime Lease-based Credentials
For non-user service access (application access to databases, container registries, remote storage, etc.) we utilise, where possible, lease-based credentials with limited scope and either single-use lifetime or, at worst case, a short TTL. In this case, if credentials are unintentionally disclosed, the impact is limited to a small subset of permissions and for a very limited time period. In the event of disclosure of an already used single-use credential, an attacker will be unable to authenticate with the service for a second time.
6.11: Secrets Management
For services for which lease-based access is not-suited, we utilise Hashicorp Vault, an open-source FIPS-140-2 compliant highly-available secrets management service. Secrets are stored encrypted, and retrieved using a one-time token to limit access to authorized processes.
6.12: Hardware Security Modules (HSMs)
As discussed above, all signing regular signing operations (network consensus, price oracles, etc.) use YubiHSM2 from YubiCo. Authentication user credentials are stored securely in Vault, and when required to unlock the HSM for signing, retrieved as a single-use wrapped token representing a short-TTL lease and the secret is never persisted to disk.
6.13: Hardware Wallets
All irregular signing activities (withdrawing, delegating, sending of assets), where the keys are not required to be 'online', are conducted using company-owned Ledger hardware wallet devices.
7: Gaps and Future Improvements
We have invested a significant amount of energy into building a very secure and highly available validator, but no infrastructure is "finished". There will always be the next improvement to make; the next defense to introduce into one’s setup and the next networks to onboard. In this section, we cover some projects or improvements that can become important themes for Chorus in the future.
7.1: Leveraging Trusted Execution Environments as an Additional Line of Defense
One new development in the infrastructure security industry is the inception of commercially usable Trusted Execution Environments (TEEs). The most well-known, and well developed, TEE is Intel SGX. TEEs such as Intel SGX allow infrastructure builders to isolate critical parts of the application code and run them in hardware enclaves. Code running in hardware enclaves has greater resistance against external attackers. Such code offers guarantees against unauthorized access and attempts to change the code even if the host machine running the enclave is compromised by an attacker.
One interesting possibility is to run Tendermint KMS code on SGX Enclaves. The Tendermint KMS code is one of the critical parts of the Chorus active/active system. Doing so would provide a line of defense against putative attackers that have compromised the validation servers. If the KMS is run on SGX enclaves, it would give the company the ability to recover against compromises of validation servers; since it would take a prohibitive amount of time/resources for the attackers to penetrate the SGX defenses.
Discussions around Intel SGX often devolve into an analysis of how strong the security guarantees of Intel SGX are. Intel hardware, including SGX, has been beset by speculative execution attacks that give vectors to penetrate the defenses of hardware enclaves. Our perspective is that Intel SGX is not the be-all or end-all of application security. It is merely one line of defense for infrastructure builders, and should be used in conjunction with other lines of defense. Intel SGX does have its utility as a line of defense, because it serves to retard attackers for long enough to make a material difference to the overall security of validator infrastructure.
7.2: Cloud Validation
Validation is a young industry. There are only 10-20 networks that are genuinely interesting enough to validate today. Over time, we foresee an explosion in the number and variety of PoS networks. Perhaps, one day, the validation problem statement might be to onboard >50, or even >100 networks every year. By comparison, we're on track to onboard 5-10 networks this year.
As the sheer number of networks to be onboarded grows, our infrastructure will need to evolve to scale onboarding costs better. We could foresee the following become bottlenecks to our infrastructure:
- YubiHSMs: The YubiHSM is a great product when there are only a few networks to validate. The HSM has all of the enterprise grade features needed with an attractive price point. The attractive price point enables validation companies to purchase a fleet of YubiHSMs (10-20) to implement more complex key management strategies. Traditional HSMs cost >$10k, pricing a similar scale fleet out of the reach of startup firms.
At scale, the YubiHSM, could be an unsatisfactory product. When multiple networks are run on the same YubiHSM; latency properties degrade. Running solely Cosmos Hub on a YubiHSM gets us a consistent signing latency of ~150 ms. When 5 disparate Tendermint networks run on the same HSM, signing latency could degrade to 225 ms 25% of the time, as a different networks start to compete for HSM signing throughput. On-boarding 50 networks every year would require us to purchase 10+ new HSMs per year to have production copies and backups. The management of such a large fleet of HSMs is complex, and prone to supply chain issues.
One alternative to the YubiHSM would be to purchase higher end devices such as those from Thales. These HSM's have two orders of magnitude greater signing capacity. The downsides are the sheer bulk of these devices (>10kg per device), the antiquatedness of their development SDKs/APIs and the complex purchase process.
The most scalable solution would be to go for a cloud based key management solution. This would have us outsource all of the physical HSM management work to a vendor such as Equinix or AWS. Interesting products in the cloud key management include AWS CloudHSM and Equinix SDKMS, although currently the former does not support signing using the ed25519 curve, which precludes its use in a number of blockchain projects to date, as this curve is a popular choice for consensus keys.
- Physical Servers: A less important bottleneck are the physical servers themselves. Over time, our infrastructure could require >20 servers in different data centers around the world. Managing such an infrastructure is definitely doable, yet the question of whether all validation servers could be made truly virtual / cloud-based looms on the horizon.
The combination of both of the above is ultimately a purely cloud validator - some setup that runs on the cloud and is very easy to scale horizontally. It is bundled with automation that allows us to onboard new networks in an automated fashion. Chorus will likely move in that direction with the evolution of the validation space.
8: Conclusion
We hope you’ve enjoyed this in-depth look at the Chorus validation infrastructure. The Chorus team is open to questions and suggestions on Twitter and in our Telegram Community channel.
In building out our infrastructure, we have sought to walk the fine line between security and agility: implementing all of the most common security best practices while ensuring agility around our ability to scale out and onboard new networks and new software. We’ve built our infrastructure for our specific needs as a distributed organisation. We are always keen to help out fellow validators with their infrastructure - give us a shout if we could be of help!